Observability
 2 minutos
2 minutos
 02/06/2022
02/06/2022


¿Qué es Observability?
En castellano la palabra “Observabilidad” no está reconocida, sin embargo, el término “Observability” en idioma inglés ha venido tomando importancia en el área de las tecnologías de información en los últimos años. Para entender a qué refiere, es necesario conocer, antes que nada, de qué manera se diferencia del monitoreo tradicional.
Monitoreo vs. Observability
El monitoreo consiste en una actividad constante que tiende a ser reactiva cuando algún evento o incidente ocurre con los sistemas. Observability va más allá, pues busca tener una visión 360° de un sistema de tecnologías de información mediante la recopilación y visualización de datos con el análisis de eventos que facilita la toma de decisiones de manera efectiva y rápida.
Para ello, se deben tomar múltiples orígenes de datos y considerar la naturaleza de la infraestructura, métricas de negocio, APMs, consumo de recursos y costos en la nube, etc.
La clave de Observability está en el cruce y la relación
existente entre datos provenientes de distintos orígenes.
¿Cuáles son los pilares de Observability?
Observability se basa en 3 pilares fundamentales para la recolección de datos:
Logs: la bitácora de todos los eventos ocurridos en el sistema. Cada evento presenta una marca de tiempo y una descripción que permiten conocer su momento de origen.
Métricas: Es la representación numérica de un atributo del sistema que puede estar ligado al rendimiento, consumo, disponibilidad y performance de los servicios.
Trazas: Es el registro de eventos relacionados entre sí en los sistemas. En ocasiones permite determinar las causas, los efectos y las posibles consecuencias de lo que está ocurriendo.
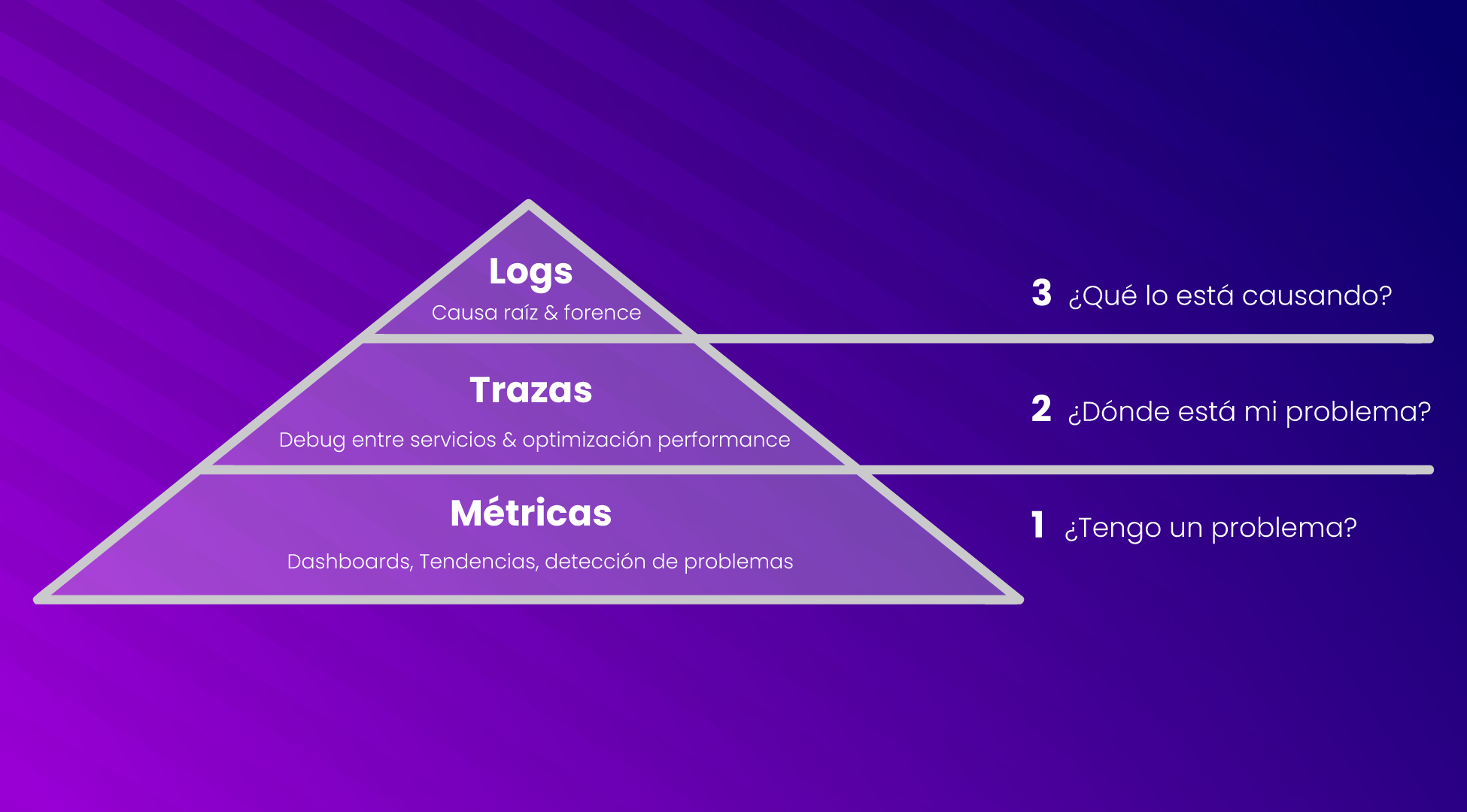
Observability permite ejecutar técnicas forenses a los sistemas de información para determinar los orígenes de algún incidente. A su vez, brinda herramientas que mejoran el rendimiento de la infraestructura y evitan la aparición de errores.
¿Cómo funciona la Observabilidad?
Para ejemplificar cómo funciona la Observabilidad, pensemos en la hora pico del uso de un sistema. ¿Por qué? Porque durante este periodo de tiempo se pueden ver grandes cantidades de requests de servicios.
Estos requests masivos pueden causar un alto uso de recursos (CPU, Memorias, Caches, etc.) y en algunos momentos originar errores, fallas, lentitud o inclusive la caída del servicio. Observability analiza las métricas de cantidad de request por segundo, consumo de CPU, memoria y disco, para conocer cómo se comportó el sistema durante esta etapa. De esta forma, si hubo algún inconveniente, la Observabilidad permite conocer en qué lugar se originó (trazas).
Una vez completada esta etapa y con la información ya procesada, se inspeccionan los logs que permitirán determinar la causa del inconveniente y dar los primeros indicios para soluciones a corto, mediano o largo plazo.
En la actualidad, con el uso de servicios en la nube, el ejemplo anterior puede reflejar que, durante periodos de alta demanda del sistema, la cantidad de recursos puede escalar de manera dinámica y automática. Así mismo, una vez finalizado ese periodo de tiempo, el consumo puede regresar a la normalidad, a sus valores mínimos.
Esto quiere decir que la aplicación de Observability permite jugar con la economía de los servicios de nube y ofrece los insumos necesarios para brindar un consumo de recursos en la nube más eficiente.
De la teoría a la práctica: el modelo de capas
Observability es un concepto. Sin embargo, existen plataformas que permiten recurrir a sus principios para crear herramientas y utilizarlas en una organización. Para ello se aplica un modelo interesante dividido en capas:
- Ingesta: Obtención de los datos desde sus distintas fuentes (Logs, Métricas, XML, CSV, TXT, End Points, APIs, SQLs, etc.).
- Procesamiento: Una vez obtenido los datos esta capa los procesa y realiza cruces de información para la obtención de modelos de relación.
- Almacenamiento: Una vez procesada la data, la información resultante se almacena para quedar disponible y facilitar su consulta.
- Visualización: Es la capa donde los usuarios finales de Observability consumen los datos, métricas, trazas y logs almacenados en forma de dashboards que facilitarán las consultas personalizadas y el análisis de la información.
Este modelo en capas brinda una serie de ventajas importantes, como la coexistencia e interoperabilidad de múltiples tecnologías, escalabilidad de acuerdo con la demanda y el posible crecimiento de las fuentes de datos. Además de brindar una plataforma en donde pueden participar administradores de sistemas, ingenieros de datos, directivos, gerentes y hasta cualquier tipo de usuarios finales.
La revolución de la Observabilidad
Observability ha llegado para quedarse. Y es que ha crecido tanto, que los líderes de la industria han apostado por la creación e implementación de tecnologías y herramientas que faciliten su adopción. AWS, Azure o GCP, son un claro ejemplo de ello. Por otro lado, empresas desarrolladoras de soluciones Enterprise como New Relic, Dynatrace, Elastic y Honeycomb han adoptado también la Observabilidad en sus productos. Además, existen otros proyectos Open Source como Prometheus de The Linux Foundation o las apuestas de The Apache Software Foundation como Kafka, Nifi, Spark y Superset, que ayudan a expandir los límites de la Observabilidad.
En conclusión, en un mundo digital como el actual en donde los datos son de vital importancia para todos los sistemas a nuestro alrededor, la adopción de Observability permite acercarse a una Ingeniería de Datos eficiente, ganando capacidad de observación, predicción y toma de decisiones. Por último, ayuda a que las empresas de TI puedan desarrollar plataformas con servicios de analíticas de datos para sus clientes y en especial, para su consumo interno, generando valor agregado a la hora de competir.








